
You're Probably Automating the Wrong Things
A framework for knowing where value actually lands

Last week we looked at RIRA- a strategy-to-execution framework for rebundling value creation in commercial real estate under conditions where AI materially changes the unit economics of analysis and content production.
This week we’re going to look at ‘The CRE Automation Matrix Framework’ - a tool for understanding where value is moving to, what to automate, and how.
WHAT THIS FRAMEWORK IS
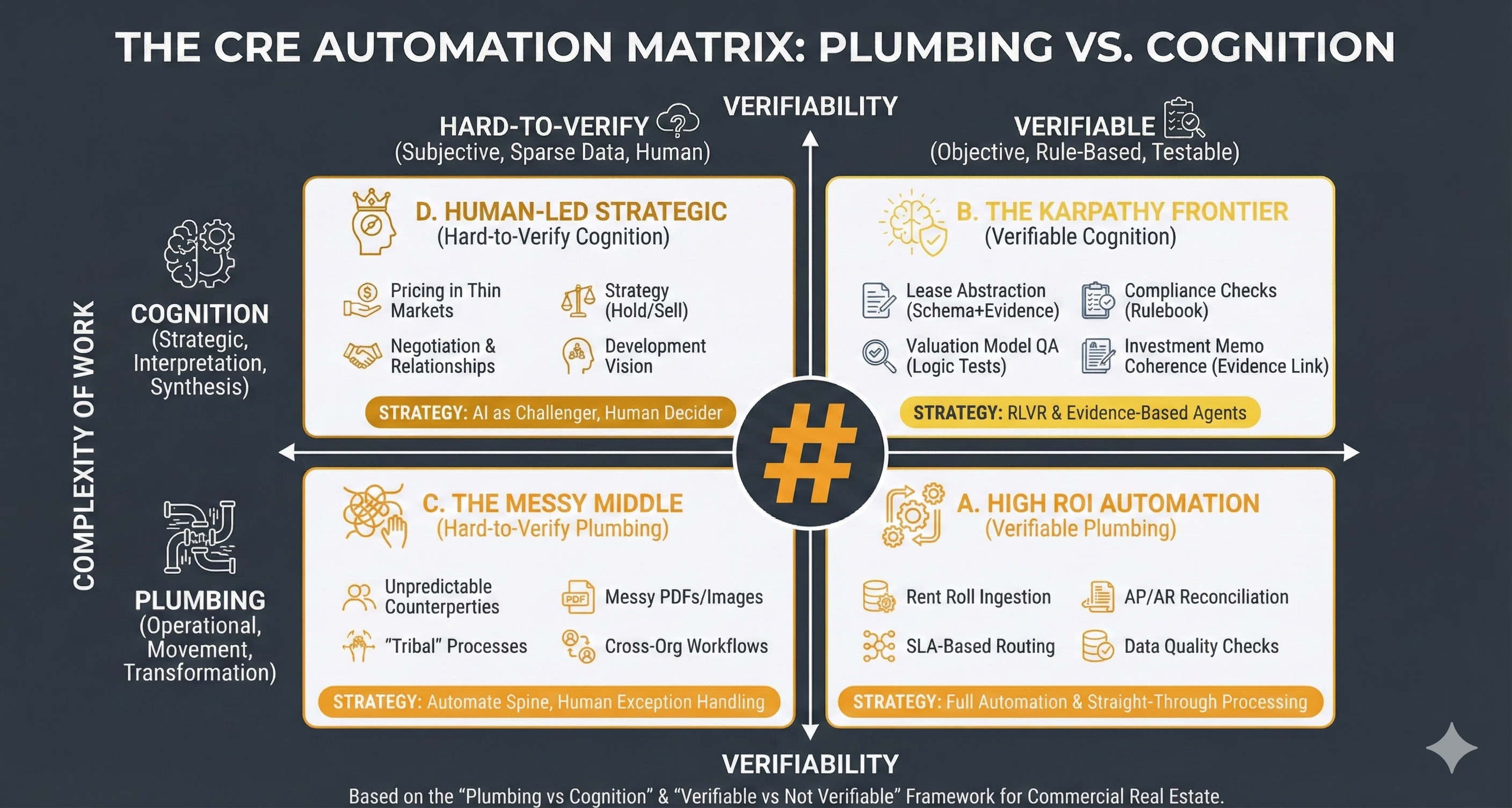
The CRE Automation Matrix is a decision framework for choosing how to apply automation and AI across commercial real estate workflows by classifying work along two dimensions:
What kind of work it is (operational “plumbing” versus strategic “cognition”)
How verifiable it is (hard-to-verify versus rule-based/testable).
Its practical purpose is to prevent two common errors:
(i) automating the wrong things (low ROI or high risk)
(ii) automating the right things with the wrong method (straight-through automation where you actually need evidence links, tests, and human exception handling).
WHY IT MATTERS: THE STRATEGIC PROBLEM
Most CRE organisations are currently “tool shopping” (Copilot, chatbots, RPA, point solutions) rather than systematically deciding where automation belongs, what must remain human-led, and what requires verifiability engineering (tests, evidence, audit trails).
This framework solves the prioritisation, design and risk control problems:
Prioritisation: Where is the highest ROI with the lowest governance burden?
Design: What automation pattern fits the reality of the work (straight-through, evidence-based agents, or human-in-the-loop)?
Risk control: Where do hallucinations, silent failures, and compliance gaps most commonly occur?
WHAT GOES WRONG WITHOUT IT
You automate cognition without verifiability
You get fluent outputs that are not defensible: investment narratives without evidence links, lease abstracts without citation, “compliance checks” that miss edge cases.
Result: reputational and financial risk.
You under-automate plumbing because it feels unglamorous
Teams chase “AI strategy” while still rekeying rent rolls, reconciling invoices manually, and firefighting data quality.
Result: the operational drag remains; AI “ROI” never shows up.
You treat messy workflows as if they were standard workflows
Cross-org tasks and tribal processes (variations, exceptions, unwritten rules) break brittle automations.
Result: compounding errors, escalation fatigue, and loss of trust in automation.
You blur accountability:
Who signed off the value?
Who verified the covenant?
Who checked the lease clause?
Without the matrix, AI adoption often smuggles in a dangerous assumption: “the model did it”.
The bottom line?
If you cannot explain how a task is verified, you are not “automating”; you are outsourcing judgement to a stochastic text generator - and hoping your governance function never notices.
WHY IT WORKS SO WELL
The power of this framework comes from the way it melds the type of work with its verifiability.
The Vertical Axis: Complexity of Work (Plumbing → Cognition)
The intent here is to understand what is the nature of the work being undertaken.
So first off you decide if a task is ‘Plumbing’ or ‘Cognition’. I.e, is it about moving, transforming, routing, reconciling, standardising or validating? In which case it is ‘Plumbing’ or is it about interpreting, prioritising, negotiating, scenario framing, decision-making, or storytelling with accountability? In which case it is ‘Cognition’.
Many tasks contain both, in which case you classify based on where the risk and value concentrate.
People make typical mistakes here: they call everything “strategy” just because it touches money. Or treat “cognition” as producing nicer text rather than making (and owning) a decision. People label anything involving writing as “strategic”, then optimise for eloquence instead of decision clarity: options, trade-offs, thresholds, owner, next action.
CRE examples might be: SLA-based triaging of incoming maintenance requests is ‘Plumbing’ whereas deciding whether to hold/sell an underperforming asset in a thinly traded submarket is ‘Cognition’.
The Horizontal Axis: Verifiability
Here the intent is to distinguish tasks where outputs can be objectively checked (rule-based/testable) from tasks where correctness is contested, contextual, or data is too sparse.
So for any task you need to ask three questions:
Is there a reference standard? (rules, schema, thresholds, contractual language, accounting logic, policy)
Can I test the output? (logic tests, reconciliation, constraints, sampling, peer review)
Can I attach evidence? (citations to leases, invoices, emails, comps, photos, source systems)
If the answer is “mostly yes”, you are on the Verifiable side. If “mostly no”, you are on Hard-to-Verify.
Typical mistakes are confusing “sounds plausible” with “verifiable”. Or assuming availability of documents equals availability of evidence (a PDF is not evidence unless you can reliably extract and cite the relevant clause). Or treating a policy statement as a test (a test requires pass/fail conditions).
CRE examples might be:
Verifiable - “Does the rent roll total match the general ledger control account within tolerance?” (reconcilable)
Hard-to-verify - “Is this tenant likely to renew if we refurbish?” (contextual, behavioural, market-driven)
So with these variables in place we get to having:
FOUR QUADRANTS
Quadrant D
Human-Led Strategic (Hard-to-Verify Cognition)
Where the intent is to protect genuinely strategic, low-verifiability decisions from premature automation while still using AI to improve the quality of thinking.
Such as here: Pricing in Thin Markets; Negotiation and Relationships; Strategy (Hold/Sell); Development Vision.
Strategically this is about: ‘AI as Challenger, Human Decider’.
Quadrant B
The Karpathy Frontier (Verifiable Cognition)
Where the intent is to capture the emerging sweet spot: tasks that feel cognitive (reading, reasoning, writing) but can be engineered to be verifiable through evidence links and tests. This is where AI can be powerful and governable.
Such as here: Lease Abstraction (Schema+Evidence); Compliance Checks (Rulebook); Valuation Model QA (Logic Tests); Investment Memo Coherence (Evidence Link).
Strategically this is about: ‘Reinforcement Learning with Verifiable Rewards’ and Evidence-Based Agents.
NOTE: Andrej Karpathy is one of the most revered AI researchers in the world and he has recently been arguing that the most promising frontier for AI capability expansion lies in domains where outputs can be verified programmatically - enabling models to learn from feedback loops rather than human labelling. This quadrant represents that frontier applied to CRE.
Quadrant C
The Messy Middle (Hard-to-Verify Plumbing)
Where the intent is to acknowledge where automation fails most often: not because the task is “hard”, but because the environment is non-standard (variable inputs, inconsistent behaviours, cross-boundary handoffs).
Such as here: Unpredictable Counterparties; Messy PDFs/Images; “Tribal” Processes; Cross-Org Workflows.
Strategically this is about: Automating the Spine, Human Exception Handling. The goal isn’t eliminating humans from these workflows; it’s ensuring they’re only invoked where they add value, not where they’re compensating for brittle automation.
Quadrant A
High ROI Automation (Verifiable Plumbing)
Where the intent is to focus attention on the “boring” work that yields disproportionate ROI because it is frequent, standardisable, and testable.
Such as here: Rent Roll Ingestion; AP/AR Reconciliation; SLA-Based Routing; Data Quality Checks.
Strategically this is about: Full Automation and Straight-Through Processing
FROM TASKS TO WORKFLOWS
Most workflows span multiple quadrants - a quarterly asset review involves Quadrant A reconciliation, Quadrant B compliance checks, and Quadrant D hold/sell judgement. The framework’s purpose is to decompose workflows into constituent tasks and optimise each appropriately.
This connects directly to last week’s RIRA framework. The ‘Redesign’ phase isn’t just about improving individual tasks - it’s about re-architecting workflows so that quadrant transitions become deliberate design decisions. Where does verification occur? Where do evidence chains form? Where does human judgement enter and exit?
The Karpathy Frontier matters here because verifiable cognition is what enables linkage. A cognitive task that produces verified, evidence-linked outputs can feed downstream automation. One that doesn’t creates a break - requiring human review not because the task demands judgement, but because its output can’t be trusted by the next process in the chain.
WHERE’S THE VALUE?
Dive deep into these quadrants and it becomes very clear where automation should occur, and how.
More importantly though, they tell you where future value lies and the future shape of the real estate industry.
Verifiable Plumbing must be automated asap - because it will be relatively easy to do so, and everybody will. Which means you have to do it but you’ll not find much value there. Short term (say up to 2 years) early movers will gain an advantage but eventually all gains will be competed away.
Hard-to-verify plumbing is why you’ll still be in business, and why per unit of output labour reduction will be limited. Because it’s where the ‘messy middle’ tasks lie; tasks that aren’t particularly high-value but are very hard to automate. This will be the refuge of the complacent, and Luddite. They’ll rely on this ‘irreducibly human’ work to see them through. The problem with that is that it will be relatively short lived - AI will ‘come for’ more and more of this work over time. As capabilities expand more messiness will be automatable.
Verifiable cognition is where good money lies. Because making it verifiable is hard, complex, detailed, and reliant on excellent systems and smart domain knowledge. Only the best companies will be able to automate this work, and it’s unlikely to be commoditised. Sure, individual Lease Abstraction will be, but maybe not easily at scale, and at maximum accuracy. And seamlessly linked in as part of wider workflows. This is where tacit knowledge will become explicit, but protected by IP rights.
The best money though will be in hard-to-verify cognition. Areas where there is genuine and likely persistent human irreducibility. This is where tacit knowledge cannot be codified, and genuine ‘wisdom’ resides. Along with, probably, some formats of proprietary data and knowledge. This is where all the due diligence has been done and is looking good, but the advice comes to ‘don’t do the deal’. This game though is played in rarified air. Getting to play won’t be easy.
This CRE Automation Matrix is the analytical follow-up to the strategic vision you’ll develop with last week’s RIRA framework. And is to be used with it, in a circular way. You’re working on your H1, H2, and H3 visions but where do the component parts sit within this matrix? Are they defensible? Is that where value will be found?
CONCLUSION
In five years, the firms that automated plumbing will be table-stakes competitive. The firms that engineered verifiability into their cognitive work will be pulling ahead. And the firms that built genuine strategic judgement—the hard-to-verify cognition that can’t be copied—will be playing a different game entirely.
The matrix doesn’t tell you which game to play. It shows you which game you’re currently in.
This the verifiable real estate of my mind. The One in question who gave all the correct answers. In time and space to live life free and well happy in a my own skin but maybe not n the end...
This nails the value migration: A gets competed away, B is where the engineering moats form, D is where human judgment remains priced.
The bit I’m unsure on is your claim that B won’t commoditise. Individual tasks will commoditise fast; the moat may be the workflow-level compounding (linked evidence chains + tests + retraining loops).
Question: do you see the enduring moat in proprietary data, process integration, or verification/reward loops?